Kubernetes Checkpoint Restore Operator
Creating a Checkpoint/Restore Operator in Kubernetes to transparent checkpoint and recover stateful applications.
The Challenge of In-Memory State in Kubernetes
Stateful applications
There are two main types of applications when handling with memory state. Applications that work without depending on the internal memory of the program are called stateless applications, this applications when failing can restart and provide the same service again without degradation. A calculator application may be a stateless application or a REST API using an external database application, both applications do not need any state to provide calculations or stateless responses to data stored outside of the application. When an application needs the internal state of memory to work as expected we call them a stateful applications. On stateful applications a failure is compromising and degrades performance, as the state that was stored in memory is lost. The application may use techniques to decrease the degradation by restarts, as saving aggregates in the database on a Event Sourcing application so we do not need to reproject every event of every aggregate. Both applications have their own challenges on scaling, we are going to focus on stateless applications in Kubernetes.
Stateful applications in Kubernetes
The support for stateful application in Kubernetes is not complete. Kubernetes provides a resource, StatefulSet, that handles applications that need to store data inside a persistent volume. These persistent volumes are managed by Kubernetes by managing the ownership of the volume each time an application starts. So, whenever a StatefulSet application restarts it must retrieve the permissions for its volume. This provides support for a small set of stateful applications, these applications are applications that requires the state in order to works but save these data outside of the application, like SQL databases. There is another set of applications that this resource do not provide support, applications that rely on the state stored in memory in order to work, either for better performance or lack of alternatives, like Redis, Event Source applications or Streaming applications. Currently, there is no Kubernetes native support for these type of stateful applications.
Native Tooling in Kubernetes and Missing Gaps
In the previous section I have talked about the lack of support in Kubernetes for stateful applications. There are some solutions on how to improve the start time of stateful applications in Linux and improve the availability of the application. These techiniques are kwnown as Checkpoint and Restoring. We are going to cover how they work in Linux and how they are working with containers and Kubernetes.
Checkpointing in Linux
There is a project in Linux that handles the Checkpointing of stateful applications in Linux. CRIU (Checkpoint Restore in Userspace) provides the ability to freeze a running application and checkpoint its state to disk. Later, we can use this checkpoint data to restore the application to the state at the time the application was freeze. From their own page this is how they describe them:
Welcome to CRIU, a project to implement checkpoint/restore functionality for Linux.
CRIU helps us to checkpoint and restore stateful applications in Linux. This can be made trought the CLI, by criu dump to checkpoint the application, and criu restore to restore the application into a new process. When CRIU checkpoints an applications the application is freeze and loses availability. So, whenever using CRIU we must take that into account so we do not degrade the performance.
Checkpointing support in Kubernetes
We have seem that there is a solution for Linux on checkpointing stateful applications. As CRIU works with namespaces it works with containers as well. So, the support for Kubernetes can be implemented over the container runtimes. Kubernetes has indeed implemented a solution for Checkpointing Pods. The Kubelet Checkpoint API allow Kubernetes users to checkpoint a container process by making a call to Kubelet, this call will then be made to the container runtime that must have support for checkpointing. This will then generate a checkpoint at /var/lib/kubelet/checkpoints with the name checkpoint-<podFullName>-<containerName>-<timestamp>.tar at the node that is running the container. This is handy as now we can use this to debug failing applications or have a history of the state of the application for further debugging. As we still need to make calls to the Kubelet API, this is not a good solution for people looking for transparent checkpointing in Kubernetes, they must use its own tools to checkpoint the application and manage the checkpoints.
Restoring support in Kubernetes
As we can see there is a support for checkpoint a stateful application in Kubernetes with CRIU using the Kubelet API. Unfortunately, there is no native support for restoring the Pod container using the previous generated checkpoint. There are some options, as we can see in this (article)[https://kubernetes.io/blog/2022/12/05/forensic-container-checkpointing-alpha/], by using buildah we can create a new container image that run the checkpoint. This can be used for debugging but is not a ready solution, we still need to use tools in order to checkpoint and restore the container in Kubernetes.
Filling the missing gaps
In order to provide transparent Checkpoint/Restore for stateful containers in Kubernetes we are going to implement an Operator that is able to register Deployments that should be checkpointed in a schedule and restore their Pods when it fails. This Operator will initially work as a single replica and with Deployments with only one replica, this makes the problem easier to work with as we do not have different states for each replica or an strategy on leader and followers.
Checkpoint/Restore Operator in Kubernetes architecture
The Operator will work as shown below:
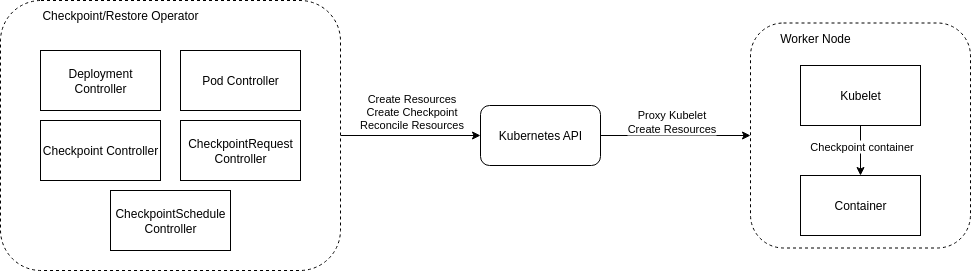
This general architecture covers the basics of the Operator. It its composed of multiple controllers for some resources. There are some known resources as Deployments and Pod, these will be used for monitor the Deployments to checkpoint and restore the failed containers, respectively. The other resources will be introduced later. The important part is that we will not communicate directly with either the container neither the Kubelet API, we are going to use the Kubernetes API as a proxy, this will enable us to require a checkpoint to a Pod using Kubernetes API as a proxy to the Kubelet API and create resources, update resources and reconcile resources (the main loop of every controller is the reconcile loop that modifies the monitored resource in order to achieve the desired state). This will enable us to communicate agnostically to a Pod and checkpoint/restore it. We are going to introduce now each of the controllers and its features in the architecture.
Security Note: Using the Kubernetes API server to proxy requests to the Kubelet (
nodes/proxy) is a powerful mechanism that simplifies authentication. However, it requires granting the operator significant permissions. In a production environment, this access must be carefully managed with strict RBAC rules to limit the operator’s reach to only the necessary Kubelet endpoints.
Let’s focus on the new resources we are introducing, the lifecycle of resources is as described in the image below:

The Deployment is created by the user and when it must be monitored, an annotation is provided for that, it will create a CheckpointSchedule resource, containing the schedule of checkpoints for that deployment. The CheckpointSchedule will create a CheckpointRequest whenever the schedule is meet, for example, if the schedule is “every 5 minutes”, every five minutes we are going to create a CheckpointRequest. The CheckpointRequest will be used as a register to request a checkpoint to the Kubelet API, when this checkpoint is request it will then create a Checkpoint resource, that when succeeded will contain the image that will be used to restore the container. Let’s dive deeper into each lifecycle of each of the created resources and understand each of the controllers.
The Deployment is created by a Kubernetes user, when it must be monitored by our Operator it will contain the annotation kcr.io/checkpoint-restore-schedule. This annotation contains the schedule we must use to create the CheckpointSchedule. So, the Deployment Controller will need to reconcile for every deployment with the annotation, creating or updating the associated CheckpointSchedule with the given schedule. A CheckpointSchedule created after this reconciliation would be like the one below:
apiVersion: checkpoint-restore.kcr.io/v1
kind: CheckpointSchedule
metadata:
name: kcr-example
namespace: default
spec:
schedule: '*/1 * * * *'
selector:
matchLabels:
app: kcr-example
status:
lastRunTime: "2025-07-30T09:54:00Z"
The schedule is given as a cron schedule. Later, the CheckpointSchedule Controller will reconcile for each resource, this will trigger a cronjob to start on the given schedule. Whenever the schedule is reached the controller will create a CheckpointRequest. We handle the request of a checkpoint in order to allow for a decoupled execution of the requests. When a request fail it should interfere with other request, so the CheckpointSchedule only creates the request and the checkpoint is made on the CheckpointRequest. A CheckpointRequest created after this reconciliation would be like the one below:
apiVersion: checkpoint-restore.kcr.io/v1
kind: CheckpointRequest
metadata:
labels:
app: checkpoint-restore
pod: kcr-example-665b8dd976-k4j6x
pod-ns: default
schedule-name: kcr-example
name: kcr-example-kcr-example-665b8dd976-k4j6x-1753869240
namespace: default
ownerReferences:
- apiVersion: checkpoint-restore.kcr.io/v1
blockOwnerDeletion: true
controller: true
kind: CheckpointSchedule
name: kcr-example
uid: ef063c6c-1e98-45a9-a074-1e2eb4e417b4
spec:
checkpointScheduleRef:
apiVersion: checkpoint-restore.kcr.io/v1
kind: CheckpointSchedule
name: kcr-example
namespace: default
uid: ef063c6c-1e98-45a9-a074-1e2eb4e417b4
containerName: kcr-example
podReference:
name: kcr-example-665b8dd976-k4j6x
namespace: default
timeoutSeconds: 300
status:
phase: Pending
It is important to highlight the CheckpointRequest lifecycle, it can assume some states during the execution of the reconciliation loop:
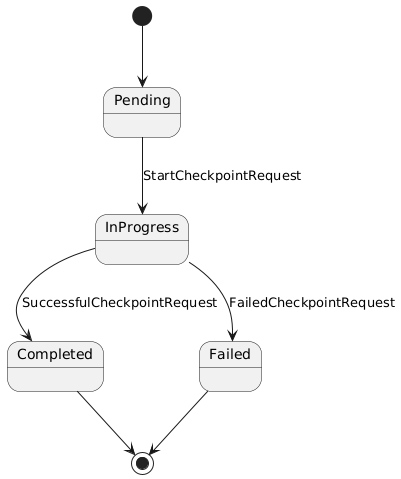
There are some phases to the request:
- Pending: this is the initial phase of the request. When the reconciliation loop begins with this phase it should request the checkpoint in Kubelet.
- InProgress: when the reconciliation loop is in progress we should not allow concurrency of requests to Kubelet. So this phase indicates we are processing the request.
- Completed: the request was completed. This does not mean we have a currently working checkpoint to restore the container, but there is a
Checkpointresource created that will generate the image to restore. - Failed: when something failed during the checkpoint request the phase will be failed and the failed reason will be available.
As the CheckpointRequest created the Checkpoint, as below:
apiVersion: checkpoint-restore.kcr.io/v1
kind: Checkpoint
metadata:
labels:
checkpoint-request-name: kcr-example-kcr-example-665b8dd976-k4j6x-1753869240
container: kcr-example
pod: kcr-example-665b8dd976-k4j6x
pod-ns: default
name: kcr-example-665b8dd976-k4j6x-default-1753869240
namespace: default
ownerReferences:
- apiVersion: checkpoint-restore.kcr.io/v1
blockOwnerDeletion: true
controller: true
kind: CheckpointRequest
name: kcr-example-kcr-example-665b8dd976-k4j6x-1753869240
uid: 3f0435f2-5063-4139-a360-535e31f05dbf
spec:
checkpointData: checkpoint-kcr-example-665b8dd976-k4j6x_default-kcr-example-2025-07-30T09:54:00Z.tar
checkpointID: kcr-example-665b8dd976-k4j6x-default-1753869240
checkpointScheduleRef:
apiVersion: checkpoint-restore.kcr.io/v1
kind: CheckpointSchedule
name: kcr-example
namespace: default
uid: ef063c6c-1e98-45a9-a074-1e2eb4e417b4
checkpointTimestamp: "2025-07-30T09:54:00Z"
containerName: kcr-example
nodeName: kind-worker
schedule: '*/1 * * * *'
selector:
matchLabels:
app: kcr-example
status:
phase: Created
We can generate the image to use in a restore. It is important to remember that the Kubelet API do not generate a working image to use in a restore process. We need to generate the image from a compressed file. This can be done using buildah, and buildah has an integration with Golang, so we are using it to build and image from a checkpoint and deploy it to a image registry. The Checkpoint has phases as the CheckpointRequest does:
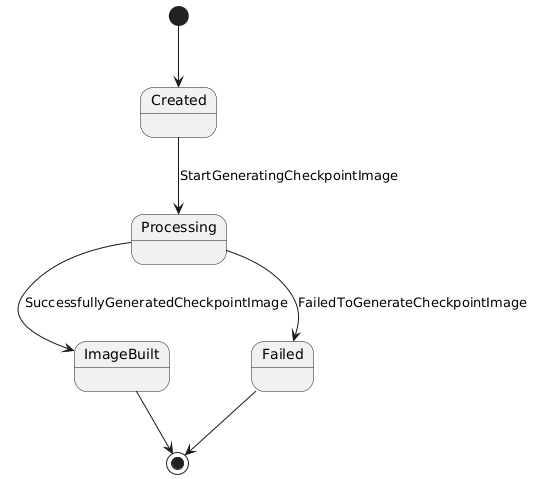
There are some phases of the Checkpoint:
- Created: the checkpoint was created by the Kubelet request and is available as a compressed file.
- Processing: the checkpoint is being processed from the compressed file, this blocks any attempt to generate concurrent images from the same checkpoint.
- ImageBuilt: when the checkpoint was converted to an image using buildah and deployed to an image registry. This is the last step in order to allow for a restore of a container.
- Failed: when some step failed, either converting the compressed file into an image with buildah or deploying it to a container registry.
When the Checkpoint reaches the ImageBuilt phase it will have the following information:
status:
checkpointImage: checkpoint-kcr-example-665b8dd976-k4j6x-default-1753869240
phase: ImageBuilt
runtimeImage: checkpoint-kcr-example-665b8dd976-k4j6x-default-1753869240:latest
The Pod Controller will reconcile for each Pod when it fails. It will search for the last Checkpoint associated to a Pod and use the available image as the recovery image. This will restart the Pod container as the last checkpointed version.
The Operator in Action: A Practical Walkthrough
Let’s use the Operator to checkpoint and later restore an application. We are going to use it with Kind running with cri-o as the container runtime as this is the only runtime supported by the operator yet. We need to tweak some configurations of Kind to make this work:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
featureGates:
ContainerCheckpoint: true
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
criSocket: unix:///var/run/crio/crio.sock
- role: worker
extraMounts:
- hostPath: ./checkpoints
containerPath: /var/lib/kubelet/checkpoints
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
criSocket: unix:///var/run/crio/crio.sock
extraPortMappings:
- containerPort: 10250
hostPort: 10250
protocol: TCP
As we need a registry connected to both Kind and the local machine, we need to add it to Kind, we can follow this tutorial or use the script at github. Now, we can use the Operator. But first, we need to build it and send it to Kind with the command make docker-build to build and the script to deploy the image to the cluster. Lastly, we can deploy the operator with the command make deploy-local IMG=controller:latest.
With the operator running we can deploy a new deployment:
kind: Deployment
apiVersion: apps/v1
metadata:
name: kcr-example
labels:
app: kcr-example
annotations:
kcr.io/checkpoint-restore-schedule: "*/1 * * * *"
spec:
replicas: 1
selector:
matchLabels:
app: kcr-example
template:
metadata:
labels:
app: kcr-example
spec:
containers:
- name: kcr-example
image: my-image
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
This deployment have an annotation kcr.io/checkpoint-restore-schedule, this indicates to the Deployment Controller that this application should be monitored for checkpoint and restore. So, when the deployment is created a CheckpointSchedule will be created. The CheckpointSchedule Controller initiates a cronjob with the given schedule that will create a CheckpointRequest whenever the schedule is hit. Then, the CheckpointRequest Controller will request a checkpoint using the Kubernetes API and this will generate a Checkpoint resource. Later, the Checkpoint Controller will use the checkpoint data generated by the Kubelet to create a workable image to run the application from the checkpoint and deploy it in an image registry. We can check this in the image below:
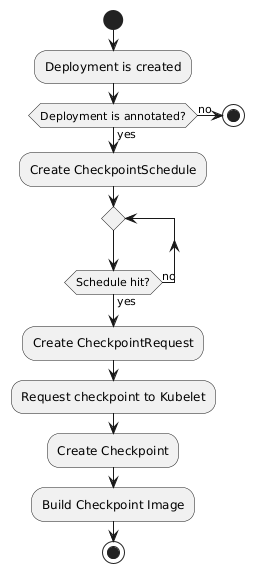
Using the image generated by the last step we can start the restore process. To initiate a restore process we can kill a Pod container using the crictl of the worker node, by running the command docker exec kind-worker crictl ps and finding the container associated with the Pod, this command lists the Pod associated with each container. Then, we can kill the container with docker exec kind-worker crictl stop CONTAINER_ID. This process will trigger the failing process of a container in Kubernetes Pod, the Pod Controller will look for the newest checkpoint and use it as the recovery image.
After the process of the restore is finished we can check that the image was changed to something like kind-registry:5000/checkpoint-kcr-example-665b8dd976-k4j6x-default-1753869840, this is the checkpointed image the Checkpoint Controller generated. The Pod will still show a fail as below:
NAME READY STATUS RESTARTS AGE
kcr-example-665b8dd976-k4j6x 1/1 Running 1 (2s ago) 13m
This concludes the checkpoint and restoring of a single replica deployment using the Kubernete Checkpoint/Restore Operator.
Conclusion
Kubernetes does not provide full support on a checkpoint and restore of stateful applications, the developed application available at github provides a Kubernetes Operator for checkpointing and restoring of stateful applications. It will work with single replica deployments working in Kubernetes with cri-o.
Futher improvements
There are some problems with this solution, first it relies on privileged containers and deployments in order for the operator to work as it need permissions to communicate with Kubelet. We can mitigate this problem by either providing the required permissions just to a Job that performs the checkpoint, limiting the interaction with Kubernetes or using the Kubelet API inside each node with a DaemonSet for the Operator.
One of the problems in the application is that we are relying on an image registry to distribute the checkpoint image. We could build the image and distribute it between the nodes in the cluster instead of the deploying it into an image registry.
Other problems involves using just the checkpoint and restore. The proposed solution requires the user to use checkpoint and restore together, even tough the periodic checkpoint can be a feature by itself. The checkpoint could be improved by providing other ways of checkpointing than making it in a schedule, we could use machine learning to predict when a container would fail to save its state for restoring later. Also, tooling involving on demand checkpoint and recovery would be great extensions.
Lastly, we could support the usage distributed deployments with more than one replica. This problem will be scoped to the range of applications, some applications implement a leader and follower approach to scale and the state is distributed between them, we would need to handle consistency as these systems work together.