Build a highly available task scheduler with ZooKeeper and Consistent Hashing
In my two previous posts, Build a highly available task scheduler with PostgreSQL and Build a highly available task scheduler with ZooKeeper leader and followers, I created a highly available task scheduler using the leader-follower design pattern. This is a great pattern to achieve high availability by distributing the operational load among the followers. We use the leader to coordinate work among the followers. While this works great, we have a constraint when a replica/node dies. If either the leader or a follower dies, we must redistribute all partitions to every follower. This can cause downtime or even inconsistencies. For example, a node that missed the latest update might think it owns partitions that are actually owned by another replica.
The core issue is that a failure in the leader-follower model is a system-wide event. If the leader fails, the entire system pauses until a new one is elected. If a follower fails, the leader must orchestrate a potentially large and disruptive rebalancing. This creates a “blast radius” that can impact the entire cluster’s stability and performance.
To solve this, we can adopt a leaderless pattern: Consistent Hashing. The primary benefit of this approach is its superior fault tolerance. By removing the central coordinator, we drastically reduce the impact of a single node failure. Instead of a system-wide halt or a “rebalancing storm,” a node failure becomes a localized event with minimal and predictable consequences. This allows the system to be not just highly available, but truly fault-tolerant.
Consistent Hashing
Consistent Hashing is an algorithm to distribute load among different nodes without the need for a central coordinator. When we are coordinating the distribution of work among nodes, we usually select a few partitions to be worked by each node. For example, in my last posts, I have added a leader that would decide which followers would handle each partition. So, in the first execution of the process, we would have something like this:
node1: 1, 3, 6
node2: 2, 4
node3: 5, 7
This is the initial distribution. When one of the nodes dies, for example node2, the leader would redistribute all the partitions among the remaining nodes, so the next distribution would be something like this:
node1: 1, 3, 4, 6
node3: 2, 5, 7
This change must be propagated to each of the healthy followers. The propagation can lead to inconsistencies while the new partitions are assigned. Also, when we scale the system to have thousands of nodes, we may end up redistributing the partitions with a high frequency that would lead to bigger inconsistencies. To solve this problem we use Consistent Hashing, which does not randomly assign partitions to each node. Instead, it uses a hash to map the node into a ring.
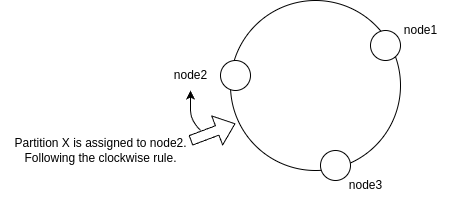
The algorithm works by mapping both nodes and data (in our case, partitions) onto the circumference of a logical circle or “ring”, typically spanning a range like 0 to 2^32-1. Each node is assigned a position on the ring based on a hash of its unique identifier (like its IP address or replica ID). To determine which node is responsible for a given partition, we hash the partition’s ID to find its position on the ring and then travel clockwise until we encounter a node. That node becomes the owner of the partition.
A naive implementation can lead to an uneven distribution of partitions. To solve this, we introduce virtual nodes (vnodes). Instead of mapping a single point for each physical node, we map multiple virtual nodes for each physical node onto the ring. This strategy ensures that the partitions are spread much more evenly across the physical nodes.
As there is no need for a central coordinator to distribute the work, this is a leaderless algorithm. Each node can independently calculate the owner of any partition, provided it has the same list of active nodes.
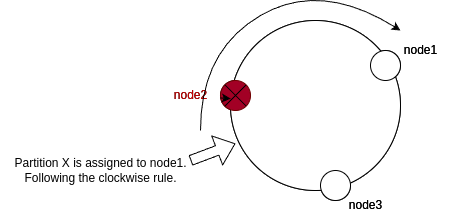
Following the initial state of the ring, when a node like node2 dies again, we do not need to redistribute the entire work. The absence of node2 in the ring assigns all the work to the next node clockwise. This enables us to not redistribute all the work among the nodes; only a few nodes will be affected by the change as shown below:
Task Scheduler with Consistent Hashing
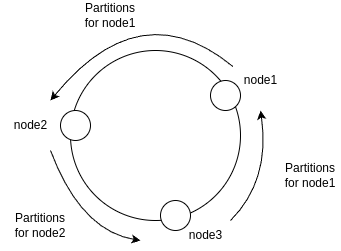
So far we have seen how we can use Consistent Hashing to map requests and nodes into a logical ring to distribute work. But, in our architecture, we have the distribution of assigned partitions to each node. We can work with the consistent hashing algorithm in a similar way. When we add nodes into the logical ring, to find out which partitions are assigned to each node we must go counter-clockwise from the node until we find another node. This enables us to map the partitions without redistributing the entire work among the nodes. In fact, we may have some partitions not being served at some point in time, but we would never get partitions being handled by more than one node at any given time. The example below shows how we are going to use consistent hashing in this case:
In order to let every node to know which nodes are currently healthy we are going to use ZooKeeper. By creating an ephemeral znode in ZooKeeper, we can create the node information into a root znode. Nodes must create a watch on the root znode to be notified when a new node is added or removed. This will enable the discovery of new nodes or old nodes without handling the entire communication between nodes like in a leader-follower pattern. As ephemeral znodes exist as long as the connection with ZooKeeper and the node is up, whenever a node dies the znode is automatically removed and the other nodes are notified.
Now, we have a way to easily distribute the work among our nodes in the Task Scheduler and a way to handle communication of the healthiness of each node. Let’s review our previous process with leader-follower:
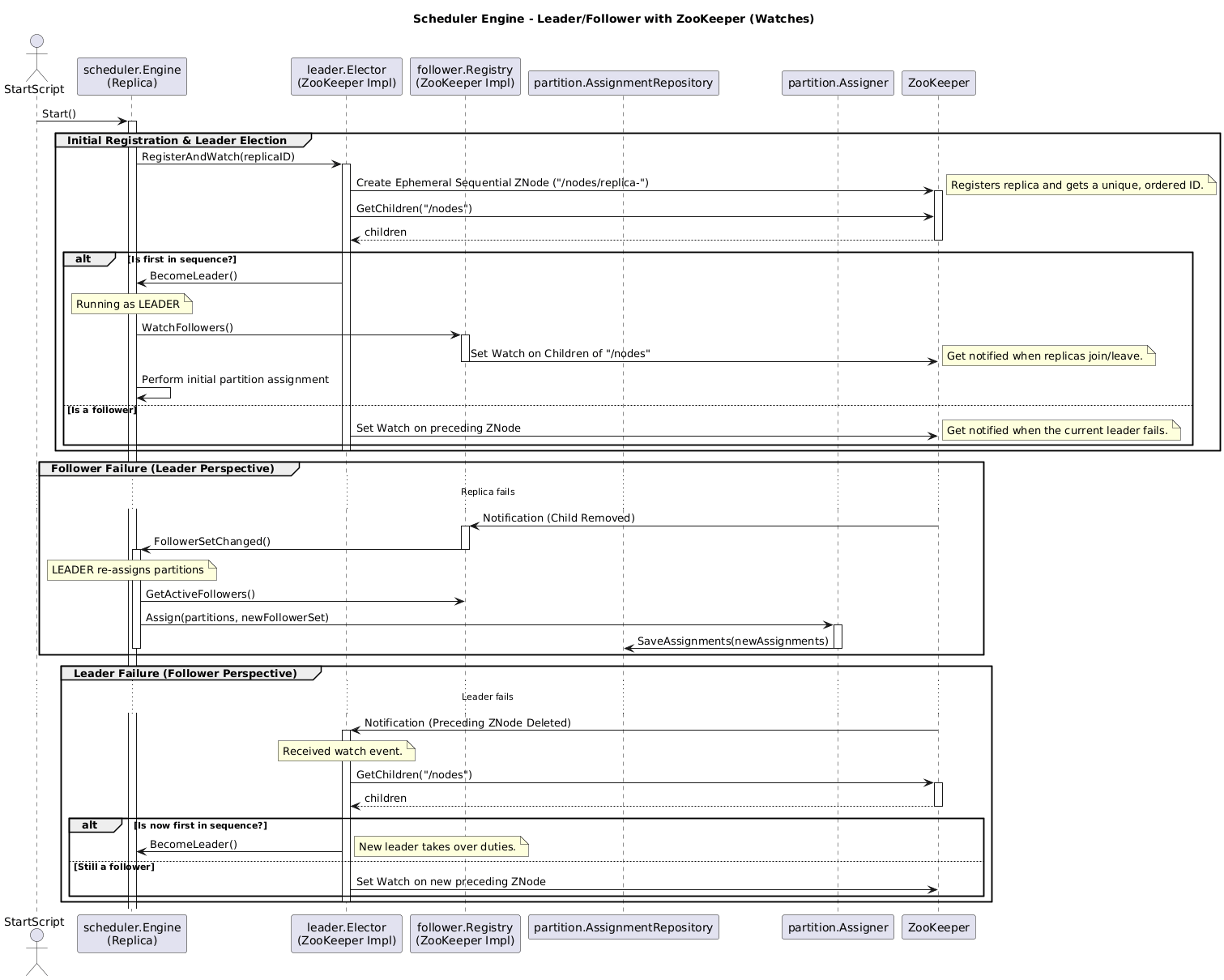
The reviewed version with Consistent Hashing is as follows:
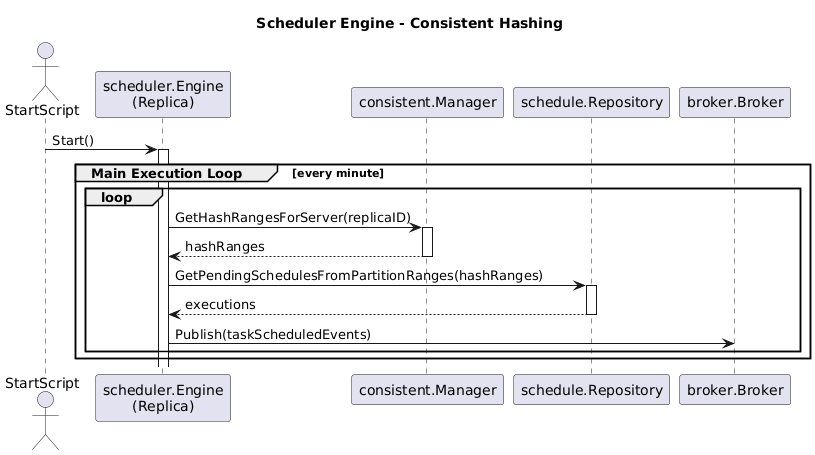
You can see there is no mention of how we handle the distribution of partitions. This is entirely handled by the ConsistentManager using watchers, as shown below:
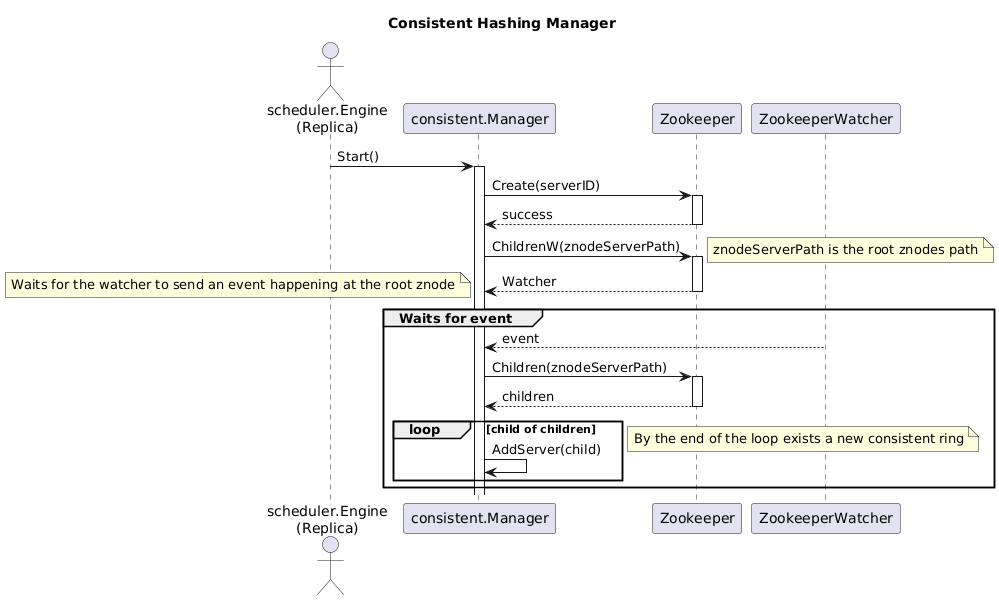
These modifications not only made the service more robust but also the domain. Now, the division between the execution of the Engine (that must publish events for the workers) is separate from the decision on the partitioning. This enables us to have cleaner code.
Conclusion
I have created a task scheduler architecture and implemented it using leader-follower pattern. This pattern has some drawbacks that could be improved by using Consistent Hashing. We modified our previous implementation of the Task Scheduler with leader-follower to use Consistent Hashing in order to achieve better consistency over the distribution of partitions among the nodes. This enabled the system to scale better.