Build a highly availability task scheduler with Zookeeper leader and followers
In a previous post I implemented the leader and followers pattern with PostgreSQL locks. That approach was easy to implement and use in local environments, but it created a single point of failure in the database. Also, the database was not distributed and we didn’t consider the problems that distribution of the database would generate, like inconsistent responses between replicas. Other problems would arise when trying to implement the best practices to keep the consistency between the replicas, like race conditions.
A better approach to implement the leader and followers pattern is to use a highly scalable, highly available distributed system, which is battle tested, like ZooKeeper. By leveraging the problem of high scale to ZooKeeper we can concentrate on business rules instead of implementing the patterns to scale, like scaling the database and handling high availability and reliability.
ZooKeeper
ZooKeeper, as declared in their own website, is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. We are going to use it to enable highly reliable distributed coordination on the Task Scheduler we implemented at this post.
To implement patterns, like leader election, ZooKeeper provides a set of primitives that applications can use to build their patterns. These primitives interact mainly with the ZooKeeper shared hierarchical namespace, which consists of a set of data registers that users can create/delete/get, called znodes. The hierarquical data structure works like a directory system in Linux systems, where each znode is part of a path, with levels separated by a slash, /, in a tree like structure.
As data is kept in memory, ZooKeeper achieves high throughput and low latency numbers. In a leader and followers implementation, we usually read state more often than we write it. The previous implementation would poll the database in a loop to check for leadership. By keeping data in memory, ZooKeeper shines under these “read-dominant” workloads, performing much better than a disk-based database for this kind of task.
Another benefit of using ZooKeeper is that it ensures the strictly ordered access to its data. So, each update receives an stamp from ZooKeeper, and it allows ZooKeeper to implement strictly ordered access. So, when a client requests data it receives the version of the data with the requested data.
Leader and Followers with ZooKeeper
I already introduced ZooKeeper and the benefits of its usage. There is still the pending issue of how to implement Leader and Followers with it. In order to implement leader and followers we must first understand two types of znodes, the ephemeral and sequential znodes.
Ephemeral znode
An ephemeral znode is a znode that exists only as long as the client’s session is active. When the client disconnects (either cleanly or due to a failure), the znode is automatically removed by ZooKeeper. This is the key feature for implementing reliable leader election, as a leader’s “lease” is tied directly to its health.
Sequential znode
A sequential znode is a znode that adds monotonically increasing counter at the end of the path. As I already highlighted earlier in this sections, ZooKeeper implements strictly ordered access, which means the counter will increase consistent between every client. So, when we create the znodes from every application node each node will receive an unique identifier that can be ordered by its value. The smallest counter will be the one that was created first.
Now, that we know how both ephemeral and sequential znodes work. How we can implement leader and followers using it?
Security Note: ZooKeeper znodes can be protected with Access Control Lists (ACLs). In a production environment, it is critical to configure ACLs to prevent unauthorized clients from modifying the znodes used for leader election, which could otherwise disrupt the entire system.
First, let’s implement the leader election. At my previous post I created an interface Elector, which contains a method IsLeader to check if a replica of the application is the current leader:
type Elector interface {
IsLeader(ctx context.Context, replicaID string, lease time.Duration) (bool, error)
}
It has also a lease time that is unnecessary with ZooKeeper as ephemeral nodes will be removed when the connection with ZooKeeper is lost. We can create a new implementation for this interface that registers the replica as an ephemeral and sequential znode in ZooKeeper in the same parent znode. To find out which znode is the current leader we can just use the first in the sequence. In order to reelect the next leader we can use the next one in the sequence and so on. It would look like this:
/nodes
1.1 /nodes/replicaId1000000001
1.2 /nodes/replicaId2000000002
1.3 /nodes/replicaId3000000003
In this example the current leader is the replicaId1 as it is the first in the sequence. Also, the previous implementation followed a loop to check if it was the leader in recurring intervals. With ZooKeeper we can setup watches in order to be notified whenever something happens with a znode, so we do not need to recheck from time to time. In order to keep the compatiblity I have not implemented this mechanism, but it would work by the replicaId2 setting a watch on replicaId1, the current leader, to be notified when it is removed so it can become the next leader. In summary, the replicaIdN would setup a watch for replicaIdN-1 in order to be notified when it is the new leader.
Another difference of our first implementation with PostgreSQL is usage of the same znodes for the register of followers. As the znodes available are all related to a live and healthy replica we can fetch the list of all znodes in the parent znode to use as the followers. This allow us to fetch this in order to check all znodes and set a watch for the parent znode to get notified whenever a children leaves. Again this was not implemented in order to keep compatibility with previous implementation.
The final flow of execution of the application is shown below:
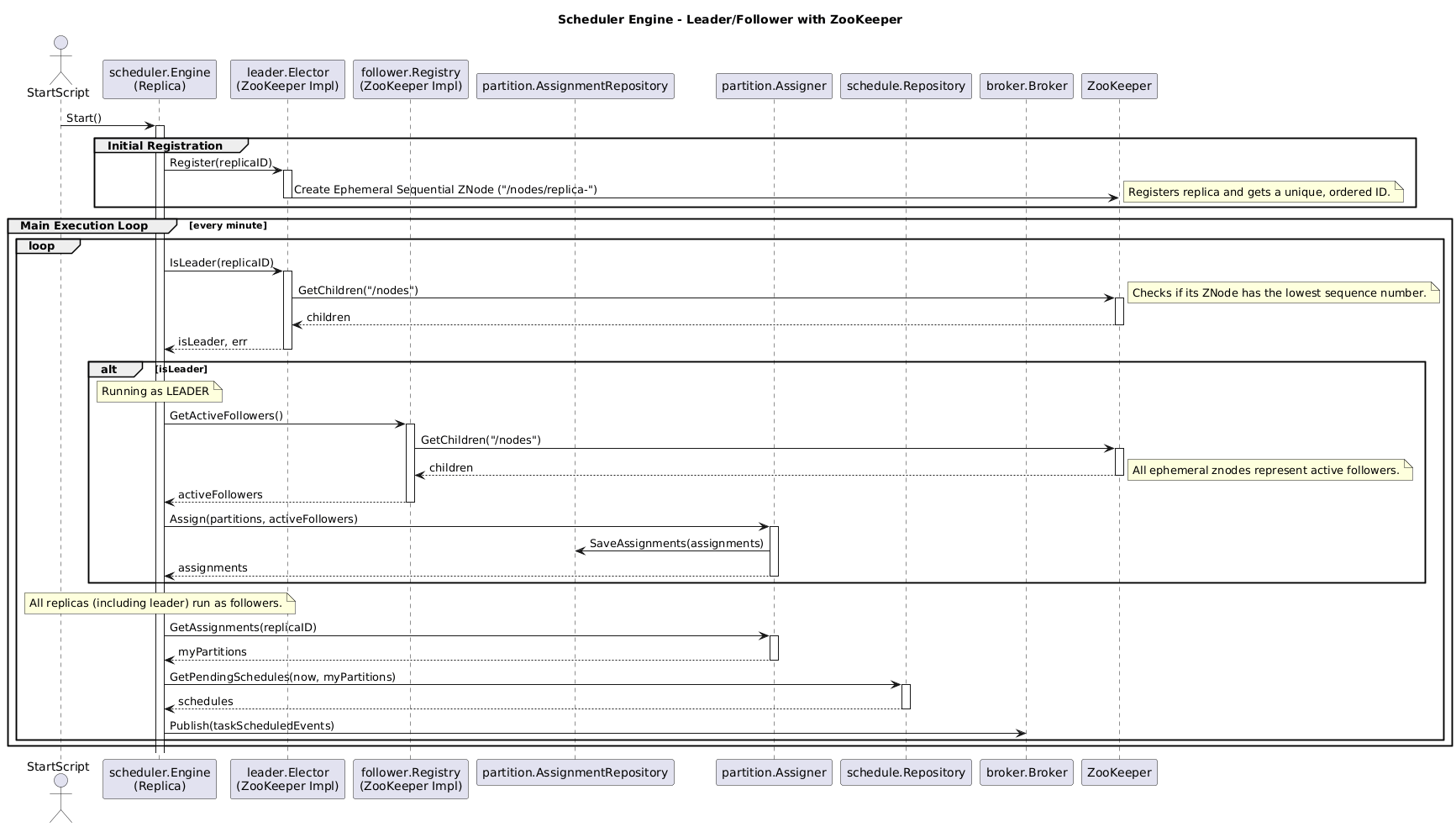
Compared to the previous version at we can see that there is not much changes. The main modifications were in the reliability and scalability of the system. Now, there is no single point of failure over the database, we can scale the database using just the non functional requirements of data not the scalability of the entire system. A better approach and performance is found in the diagram below using watches:
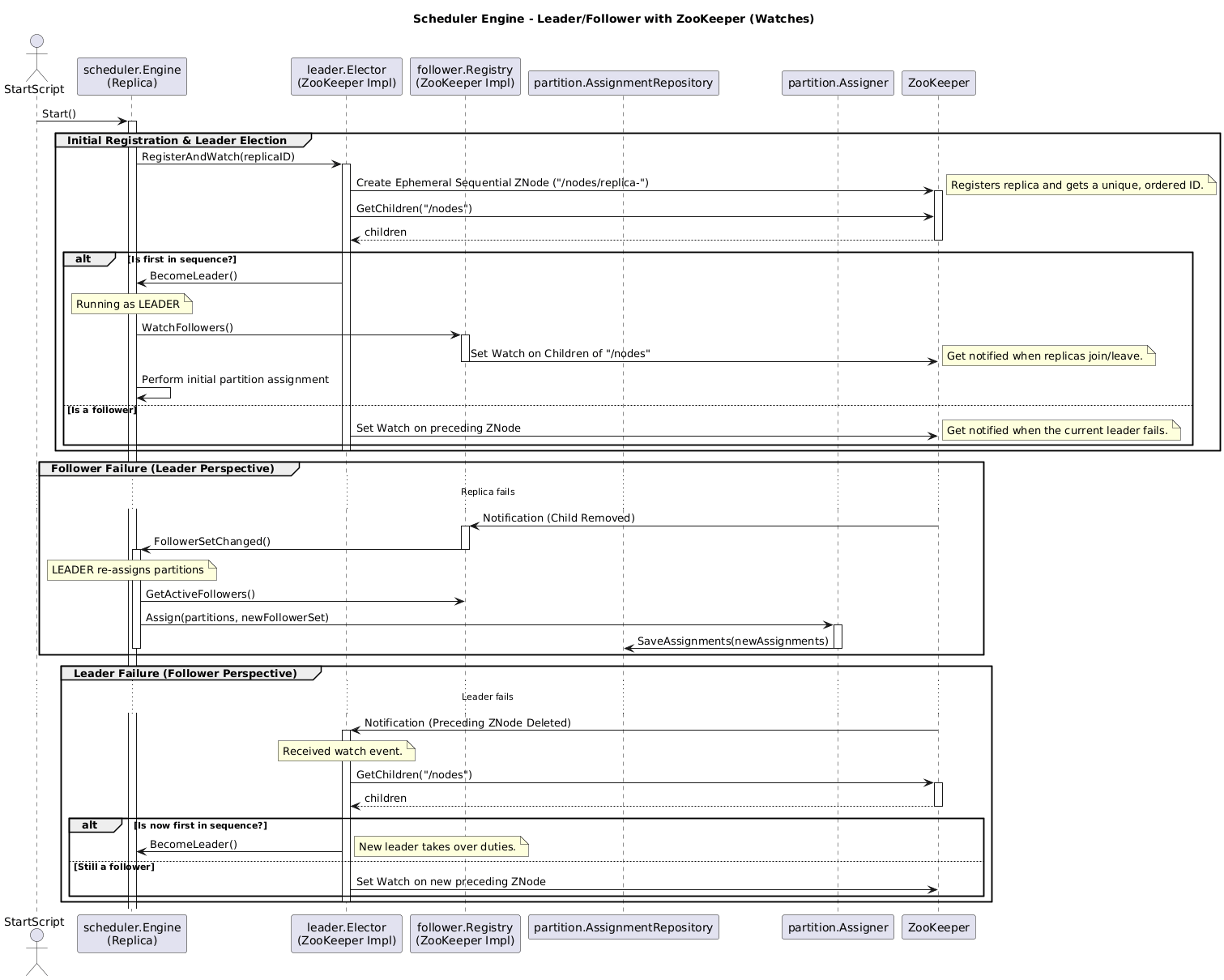
As you can see the version with watches create an event like architecture. Whenever a znode disconnects we receive a notification and act accordingly to it. The number of requests made to ZooKeeper also decreases as we are not checking znodes in a loop. If we are using a high number of replicas it is better to use the approach with watches as it is more resilient and decreases the load over ZooKeeper.
Conclusion
In the first post for the Task Scheduler with Leader and Followers we have implemented the algorithm using PostgreSQL only. This introduced a single point of failure of the entire application, also the constraints on scaling the database were divided between the data itself and the replication of the application. It would be harder to scale the application with these constraints.
In this post we introduced ZooKeeper as a highly available and scalable centralized service to handle our leader and follower algorithm. By relying on the ZooKeeper battle tested implementation we remove the single point of failure from the database and removes the overhead on implementing all the difficult algorithms to keep a total order distributed data. Now, the database can be scaled based on the data it holds and not the scalability of the system.
As a way to show two approaches on ZooKeeper we have implemented both a backward-compatible version with the PostgreSQL version and more scalable one. The scalable solution with watches allow us to decrease the load over the ZooKeeper and the loops in our own application, working with an event like architecture receiving notifications whenever a znode is deleted or created. Under highly scalable systems as in this example the usage of watches is a must.
By allowing the ZooKeeper to take the load of handling with high availability we can work on the business rules and not get the same bugs and complications of developing the highly availability system itself. The implementation of leader and followers work for this application but I want to test another solution. In the next post I will implement a Consistent Hashing algorithm with ZooKeeper to create a leaderless solution.